Every day, millions of people type prompts into ChatGPT, Gemini or Claude and get responses that feel almost human. But most people don’t realize model has no idea what it’s about to say. Not the full sentence, not even the next word. It’s generating your response one piece at a time, and each piece is a probabilistic guess over a 100,000 options. In this post, we’ll see exactly what happens from the moment you hit “Send” to the moment the text appears step by step.
Basically five things happen when you send a prompt to an LLM:
graph LR
A[Tokenize] --> B[Embed]
B --> C[Transform]
C --> D[Probabilities]
D --> E[Sample]
style A fill:#FFF4E6,stroke:#F59E0B,stroke-width:3px,color:#000
style B fill:#FFF4E6,stroke:#F59E0B,stroke-width:3px,color:#000
style C fill:#F3E8E8,stroke:#991B1B,stroke-width:3px,color:#000
style D fill:#F0F7ED,stroke:#84CC16,stroke-width:3px,color:#000
style E fill:#FFF4E6,stroke:#F59E0B,stroke-width:3px,color:#000
- Tokenization: Your text becomes pieces called tokens.
- Embedding: Each token is converted into a vector of numbers.
- Transformation: These vectors are processed through multiple layers of the model to capture context and meaning.
- Probability Calculation: The model calculates probabilities for the next token based on the processed information.
- Sampling: The next token is selected based on these probabilities, and the process repeats until the response is complete.
Let’s look at each step in a bit more detail.
1. Tokenization #
LLMs don’t read words, they read tokens. If you visit OpenAI’s tokenizer tool, you can see how different words and phrases are broken down into tokens. Most tokens are for the words, but some are for parts of words, punctuation, or even spaces. Tokenizers are trained on text data to find efficient patterns This happens before the model ever sees the input text. It’s a preprocessing step, not the neural network deciding how to break down the text. Commonn words like “the” or “and” are usually single tokens, while rare or complex words may be split into multiple tokens. For example, the word “indistinguishabe” might be broken down into “ind”, “ist”, “ingu”, “ishable”.
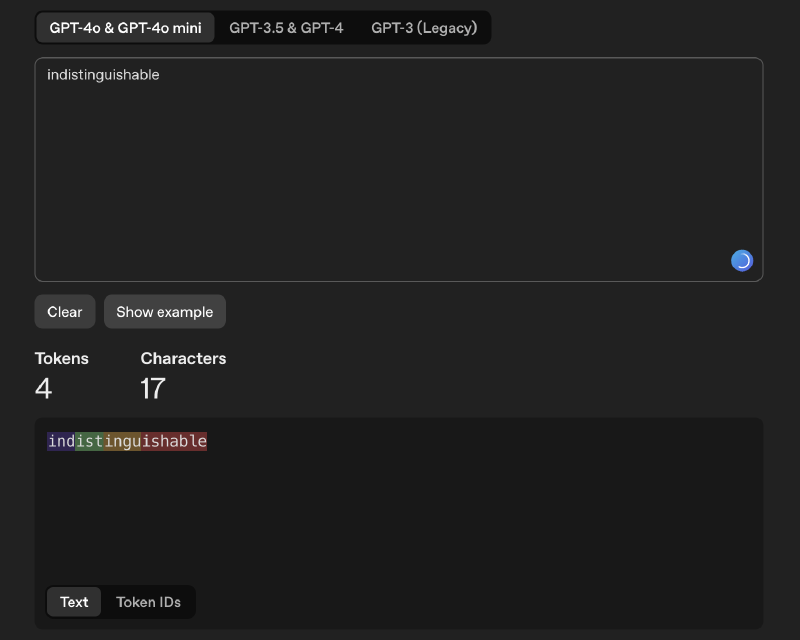
Why does it matter to you? When an API says you have a limit of 4,000 tokens, it’s counting these pieces, not words. So a prompt of 1,000 words might be 1,200 tokens, depending on the words used.
Every token is then mapped to a unique integer ID based on the model’s vocabulary.
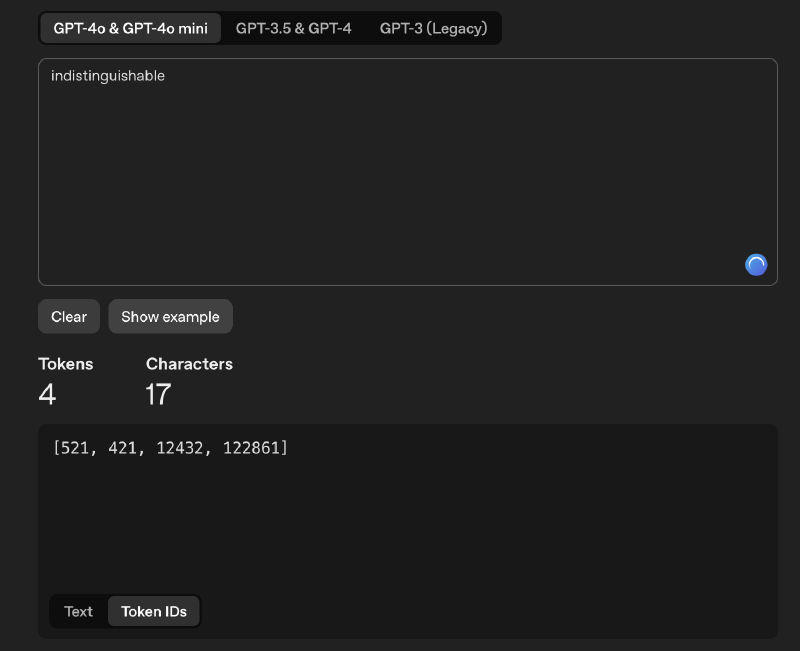
So the words become a sequence of token IDs that the model can process. But numbers alone don’t carry meaning. That’s where embeddings come in.
2. Embedding #
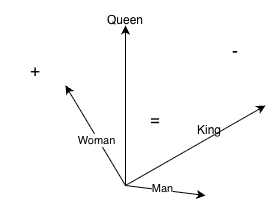
A token ID is just a number. The model needs to understand what it means. So every token ID is converted into a vector, a list of numbers representing its meaning. These vectors have thousands of dimensions. GPT-3 users over 12,000 dimensions per token. Plus these aren’t just random numbers. They are cordinates in a meaning space where similar words are closer together. Words like “king” and “queen” will have vectors that are close in this space, “python” and “snake” will be near each other, while “king” and “python” will be far apart. There is a famous demonstration. If you take the vector for “king”, subtract “man”, and add “woman”, you get a vector very close to “queen”. The model learns gender relationships just from text patterns.
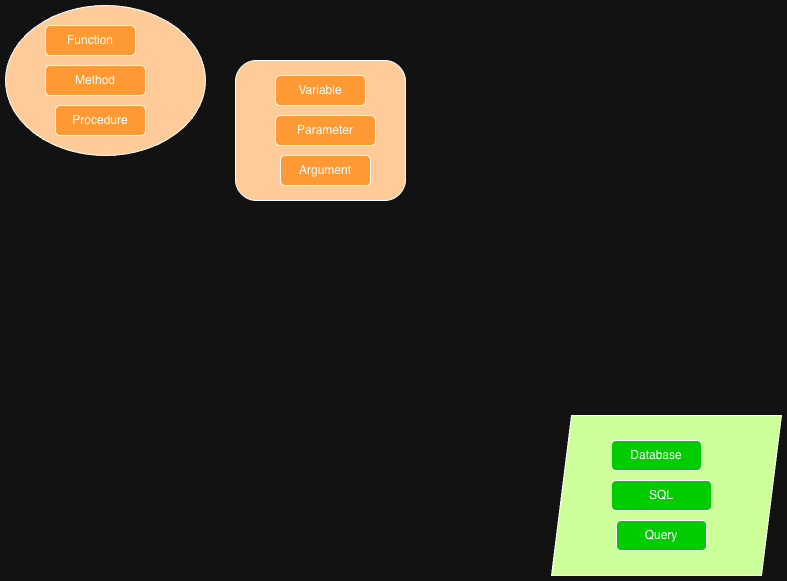
Look at below embedding space for programming terms. functions, methods, and procedures are all clustered together, while variable, parameter, and argument form another cluster nearby. Database, SQL, and query are grouped together but further away from the programming concept clusters.
This is how the model understands relationships between words. PHP and Python are both programming languages, so their vectors are close. But Python is also a snake, so it has some distance from PHP. These relationships are learned from the vast amount of text the model is trained on. Not because someone told it, but they appear in similar contexts. These rich vectors then flows into the transformer.
3. Transformation #
Your embedding vectors enter a neural network with billions of parameters. But let’s focus on the one mechanism that makes it all work. Attention. Imagine a spotlight operator in a theater. When music shifts to a new character, the spotlight moves to highlight them. Attention works similarly. When processing each token, the model decides which other tokens to focus on.
Let’s take a simple sentence: “The apple fell from the tree because it was ripe.” What does “it” refer to? The apple or the tree? When the model processes “it”, it assigns higher attention weights to “apple” and lower weights to “tree”. Even though “Tree” is closer in position, “apple” is more relevant for understanding “it”. The model learns these patterns from millions of sentences during training. This attention calculation happens multiple times in parallel through what are called attention heads. Different heads can focus on different relationships. And then this whole layer is repeated many times, GPT-3 has 96 layers, LLaMA 3’s 70 billion parameter model has 80 layers. Each layer refines the representation and builds more abstract understanding. What comes out are vectors that now encode not just individual token meanings, but rich contextual information about the entire input.
4. Probability Calculation #
The transformer has processed your input. Now it needs to decide what token to generate next. The final layer produces a score for every token in the vocabulary. Yes, every single one! LlaMA 3 has a vocabulary of over 100,000 tokens. Each gets a score. These raw scores are called logits. We apply a mathematical function called softmax to convert these logits into probabilities that sum to 1. The higher the score, the higher the probability. So if “apple” has a high score after processing “The apple fell from the tree because it was”, it will have a high probability of being chosen next. This is the core reality of LLM generation. The model doesn’t decide what to say. It produces a probability distribution over all possible next tokens. Your final response is just one path through an enormous space of possibilities. But how do we pick one token from this distribution?
5. Sampling #
This is the step where you have some control over the model’s creativity. The simplest method is greedy decoding. You just pick the token with the highest probability every time. This approach is consistent but boring. That’s where technique like temperature comes in. Temperature adjusts how confident the distribution is. Low temperature sharpen the distribution, making high-probability tokens even more likely. High temperature flattens the distribution, giving lower-probability tokens a better chance. This leads to more diverse and creative outputs. But push it too high and outputs often become incoherent.
Another method is top-p sampling. Instead of considering all tokens, you only consider the smallest set whose cumulative probability exceeds a threshold p (like 0.9). If you are writing code, you might want low temperature and top-p of 0.8 for more predictable results. For creative writing, higher temperature and top-p of 0.9 or 1.0 can yield surprising outputs. When you set these parameters in an API call, you are directly shaping this selection process. Now the chosen token is added to the input sequence, and the whole process repeats.
The Loop #
We generated one token. Now we append it to the input and run the entire process again. Tokenization, embedding, transformation, probability calculation, sampling for every single token. This continues until the model produces a end of sequence token or hit a length limit. This is why generation slows down for longer outputs. Every new token requires attention over all previous tokens. This is why the model genuinely has no idea what it’s going to say next. There is no hidden script, no planned sentence waiting to be revealed. At token 10, token 50 is not determined yet. Each word is decided only when it’s that word’s turn to be generated based on everything that came before.
Hallucination #
When LLMs hallucinate, they are not lying. They are generating text that pattern matches to what a confident, true sounding response looks like. The probability distribution does not know truth from plausibility. The implication, always verify factual claims, especially when the model sound confident.
Temperature #
Temperature does not make the model more or less creative. It makes them more likely to pick less probable tokens. Creativity is human interpretation of that randomness. The implication for determinstic tasks, coding, extraction, formatting, use low temperature. Don’t leave it to chance.
Context Limits #
Context limits are not just arbitrary product restrictions. They are computational realities. Attention has quadratic complexity. Every token must attend to every other token. The implication, when you hit context limits, it is not the company being stingy. It’s the architecture hitting physical limits.