As artificial intelligence continues to evolve, new models are being developed to push the boundaries of what machines can achieve. If you’re a developer or AI enthusiast, it’s a well known fact is for coding tasks, Claude models or OpenAI’s Codex models are often preferred, but now, a new player has entered the scene: the name is GLM-4.6, a cutting-edge AI model from China that is making waves in the AI community. In this article, we’ll explore our new potential new pair programmer, GLM-4.6 model.
What is GLM-4.6? #
GLM 4.6 is the latest iteration of the General Language Model (GLM) series developed by Zhipu AI (also known as Z.ai), a Chinese AI company. The model was released in late September 2025. It’s an open-weight model designed with a focus on advanced agentic capabilities, reasoning, and coding. This model uses a Mixture of Experts (MoE) architecture with approximately 357 billion total parameters, out of those parameters, about 35 billion are active during inference. This makes it computationally efficient compared to dense models of similar scale.
GLM 4.6 supports a context window of 200,000 tokens. It’s predecessor, GLM 4.5 only supported 128,000 tokens. This will allow this new LLM to handle more complex, long running tasks like multi-turn agent interactions. Users can access the model through Z.ai’s API, chat interface, OpenRouter, and for local deployment via Hugging Face or ModelScope repositories. The Z.ai has optimized the model both vLLM and SGLang frameworks.
Key Capabilities of GLM-4.6 #
-
Agentic tasks: GLM-4.6 has strong performance in tool use and search based agents. It has a better integration into frameworks for real world applications like browsing and command line operations.
-
Reasoning: GLM-4.6 has a improved logical reasoning. This allows tool use for more accurate results in math, logic and multi step problems.
-
Coding: This model has a strong coding ability, debugging, data analysis, algorithm design and even front end development with modern look and feel.
-
Writing and role-playing: The model aligns closely with human preferences for style, readability, and naturalness.
-
Efficiency: GLM-4.6 completes tasks using about 15-20% fewer tokens than GLM-4.5. This makes it more cost effective, so users can get more done with less.
Improvements Over GLM-4.5 #
Z.ai has built GLM-4.6 upon GLM-4.5, targeting key improvements.
- This new model has a larger context window of 200,000 tokens, up from 128,000 in GLM-4.5. This allows it to handle longer conversations and data.
- Scored higher on coding benchmarks and real world coding tasks. This includes better code generation and debugging.
- Agent performance has been enhanced, especially in search and tool integration.
- During inference, GLM-4.6 has better reasoning with native support.
- When writing content, GLM-4.6 produces more human-like natural text.
Comparison with Other Models #
GLM-4.6 has proved itself as a strong competitor to other leading coding models. It obviously outperforms its predecessor, GLM-4.5, but it also holds its own against proprietary models like OpenAI’s GPT-5 and Anthropic’s Claude Sonnet 4. The new model has shown competitive performance in some metrics compared to these models while being more cheaper (1/7th the cost via certain plans) and faster. GLM-4.6 stands out for its MoE efficiency and agentic strengths, especially against open source models like Llama 3.1 405B (from Meta) and DeepSeek V3.1 (from DeepSeek AI), but it sometimes falls short in raw scale for general tasks.
On community leaderboards like LM Arena and similar, GLM-4.6 consistently achieves top rankings among open-weight models, often placing in the top 4 overall with an ELO score around 1442. It has the highest scores for categories like creative writing and coding (#3 on hard prompts and code arenas). State of the art models like GPT-5 and Claude Sonnet 4 typically have ELO scores in the range of 1400-1460 in similar benchmarks. This shows that GLM-4.6 is a very capable model, especially considering its open-weight nature.
Below is a comparison table summarizing capabilities of coding and related tasks of GLM-4.6 against other popular models:
| Benchmark | GLM-4.6 | GLM-4.5 | Claude 4 Sonnet | DeepSeek V3.1 | GPT-5 | Llama 3.1 405B |
|---|---|---|---|---|---|---|
| LiveCodeBench v6 (coding accuracy) | 82.8 | 63.3 | 84.5 | N/A | ~83–85 (similar to Claude) | ~80 |
| SWE-Bench Verified (software engineering) | 68.0 | 64.2 | 77.2 | ~65–70 | 75–78 | 74.5 |
| BrowseComp (browsing/agent tasks) | 45.1 | 26.4 | N/A | ~40 | N/A | N/A |
| CC-Bench Win Rate (real-world multi-turn coding) | 48.6% win vs Claude | 50% win vs GLM-4.5 | Baseline | Outperforms | Similar to Claude | Competitive |
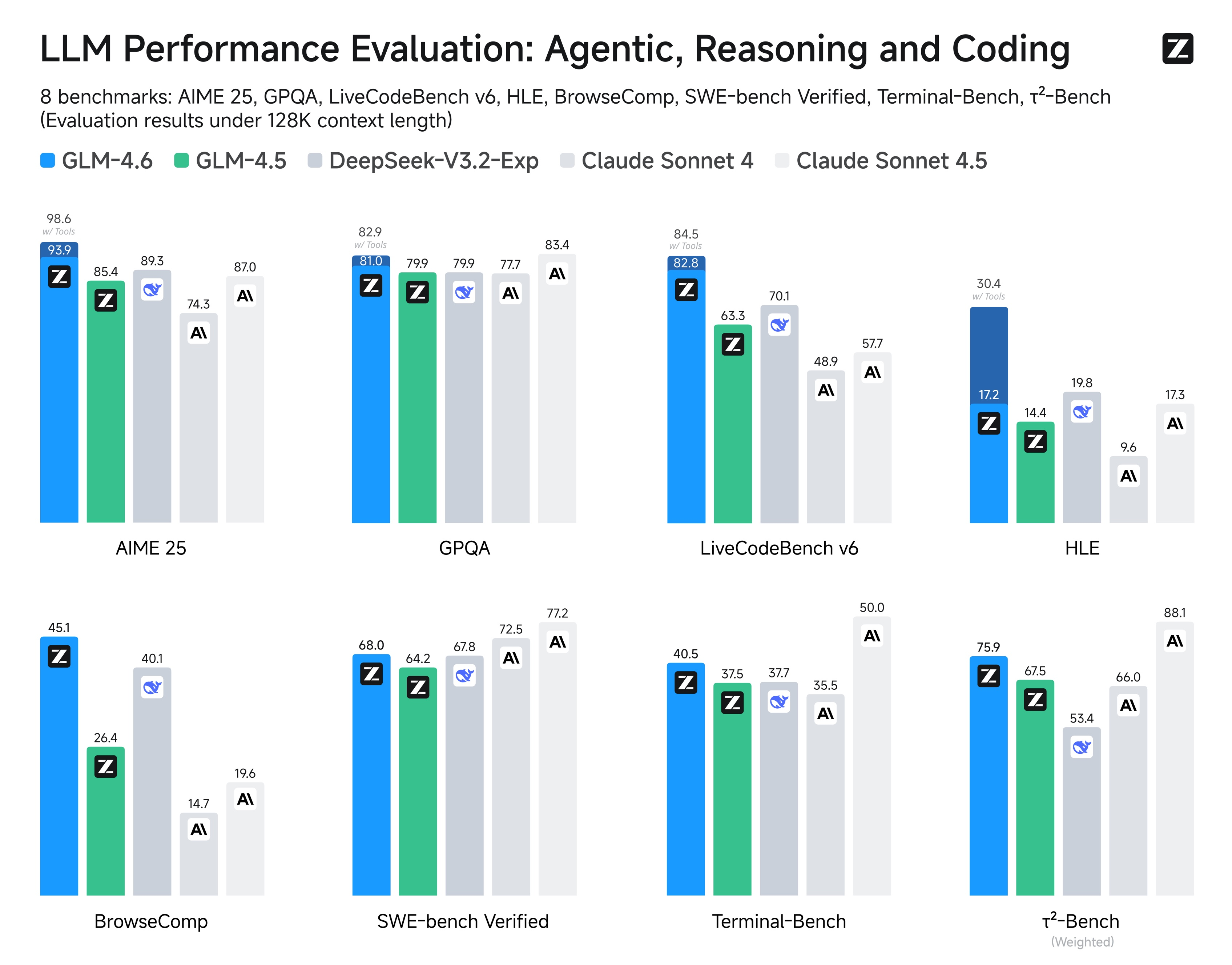
- Vs. Claude 4 Sonnet: GLM-4.6 shows very close performance to Claude 4 Sonnet in coding benchmarks (near parity with 48.6% win rate in multi-turn tasks) but Claude still has a slight edge in challenging problems and balance across tasks, but GLM-4.6 is often 10x cheaper to use.
- Vs. GPT-5: Indirectly comparable via Claude (which GPT-5 trades blows with); GLM-4.6 matches in reasoning and coding efficiency but may trail in multimodal capabilities.
- Vs. DeepSeek V3.1: GLM-4.6 outperforms latest DeepSeek models in coding and agent tasks, with win rates over 50% in comparisons.
- Vs. Llama 3.1 405B: GLM-4.6’s MoE design makes it faster and more efficient for inference. This gives better agentic integration, but Llama shines in general open-source versatility.